
校招面试题汇总
收集校招面试中遇到的基础问题。
本人校招已结束,故停更。后面随缘更新。
八股
C++
C++构造函数能否为虚函数
不能,有两点原因
使用角度:虚函数主要用于在信息不全的情况下,使得重载的函数得到相应的调用。构造函数的目的是初始化实例,使用虚函数在这里没有实际意义。而且,构造函数是在创建对象时自己主动调用的,不可能通过父类的指针或者引用去调用,因此构造函数没有必要是虚函数。
实现角度:在C++中,对象的虚表指针(VPTR)是在构造函数调用后才建立的。因此,在调用构造函数时还不能确定对象的真实类型(因为子类会调用父类的构造函数),并且构造函数的作用是提供初始化,在对象生命周期中仅运行一次,不是对象的动态行为,也没有必要成为虚函数。
*析构函数与构造函数的区别:虚函数的作用在于通过父类的指针或者引用来调用它的时候可以变成调用子类的那个成员函数。而析构函数可以是虚函数,因为我们往往通过基类的指针来销毁对象。如果析构函数不是虚函数,就不能正确识别对象类型从而不能正确调用析构函数,可能会导致资源泄露*
C++的构造函数中能否使用throw
不能,原因:
构造函数异常的问题:如果构造函数抛出异常,对象的构造会被认为是失败的。这意味着对象没有被完全构建,因此其析构函数不会被调用。这可能导致资源泄露,因为构造函数中分配的资源没有被适当地释放。
异常安全性:在构造函数中抛出异常可能会破坏异常安全性。如果异常在构造过程中抛出,那么已经构造的成员和基类部分需要被清理,这增加了代码复杂性和出错的风险。
资源清理:如果构造函数抛出异常,C++标准规定,已经构造的成员变量和基类的析构函数将被调用以清理资源。但是,对于局部变量或动态分配的资源,如果没有适当的异常处理机制,它们可能不会被清理,从而导致内存泄漏。
C++的优先队列底层是怎么实现的
堆可以通过在线性数组里维护一个平衡二叉树实现。对于坐标位置
大顶堆需要支持插入以及删除操作,其实现如下:
- 插入: 将新元素放在数组队末,假设新元素位置为
,比较其与父节点 元素的大小。若其大于父元素,则将其与父元素的位置交换。循环这个过程直到该元素到达位置0或其小于父元素。 - 删除:去除0号元素,将队尾元素放到0号位置。假设队尾元素位置为
, 找到其与两个子元素 中最大元素 。若 交换i,j 位置。重复这个过程直到队尾元素达到队尾或 。
这种操作方式可以保证存储堆的线性数组元素之间没有空隙,进而保证节点
Python
Python的装饰器
装饰器是一种函数式编程思想的产物,一个装饰器是一个函数,其输入是函数,其输出是函数。装饰器可以在不修改输入函数源码的条件下给函数添加额外的操作。一个装饰器实例如下:
1 | from functools import wraps |
这里@wraps 关键字能保证被修饰函数a_func的反射属性不被装饰器修改,如果不添加warps关键字,print(a_function_requiring_decoration.__name__) 的输出结果为wrapTheFunction。
Python的GC机制
总的来说,python的GC可以分为2种情况
- 对于一般对象,用引用计数跟踪对象被引用的次数。当引用的次数减到0时,对象自动被GC回收。
对于产生循环引用的对象,GC使用标记清除算法。在标记清除中,python会从根对象出发遍历所有可达节点并给每个可达节点做标记,对于不可达节点,则清除这些对象。标记清除算法只会在手动调用
gc.collect()以及达到分代回收的阈值的时候启动。对于所有对象,python会将其分为3代。刚被创建的对象为第0代,每次gc过后,所有对象会被挪到下一代。当某一代对象的数量达到给该代设计的阈值时,python对这一代对象实施GC。
设计模式
单例模式有几种实现方式
又名茴香豆的茴有几种写法。
关于单例模式的介绍直接cv
单例模式(Singleton Design Pattern)保证一个类只能有一个实例,并提供一个全局访问点。
单例模式的实现需要三个必要的条件:
- 单例类的构造函数必须是私有的,这样才能将类的创建权控制在类的内部,从而使得类的外部不能创建类的实例。
- 单例类通过一个私有的静态变量来存储其唯一实例。
- 单例类通过提供一个公开的静态方法,使得外部使用者可以访问类的唯一实例。
另外,实现单例类时,还需要考虑三个问题:
- 创建单例对象时,是否线程安全。
- 单例对象的创建,是否延时加载。
- 获取单例对象时,是否需要加锁(锁会导致低性能)。
游戏中常用的3种实现:
饿汉式:在程序开始时直接加载
1 | // A.h |
优点:线程安全,不会有锁带来的性能额外开销
缺点:不是延迟加载,会带来额外的内存占用。无法确定对象a初始化的时机。
懒汉式: 在运行时加载。
1 | // A.h |
优点:线程安全,支持延迟加载
缺点:对于需要频繁访问的情况,锁会带来严重的额外性能消耗。
双重检查 :兼具懒汉式和饿汉式的优点。
在锁之外额外加一次检查避免频繁的加锁操作。
1 | // A.h |
Unity
Unity的几种Update函数,各有什么作用
图形
如何光栅化一个三角形
计算屏幕像素每个点对三角形的重心坐标。
对于像素点
当
否则,像素在三角形之内。
给定法线和入射方向如何计算反射方向
思路:将入射方向
将垂直于法线的量反向并于平行量相加得:
解释一下PBR模型
严格来说PBR是一个很宽范的概念,其描述了构建物体表面的光照模型中一个十分重要的原则: 能量守恒原则,既这个光照模型反射的能量不能大于输入的能量。
可以通过白炉测试判断光照模型是否能量守恒:将光照模型放到
能量守恒 原则在光线追踪中十分重要,这意味着渲染的结果能否收敛(画面整体不会随着采样次数的增加变亮或变暗)。然而,在无需采样就能得到结果的实时渲染中并没有那么重要。我认为工业界采用PBR的原因可能有三点。
- PBR规范了游戏工业资源生产流程,美术只需要按照PBR流程制作资源, TA只需要在PBR的基础上调教效果。
- 在学术界基于PBR的各种材质模型十分丰富,工业界能站在巨人的肩膀上沿用前人的研究果实。
- 各种基于预计算的全局光照算法的流行。在实时渲染中采用和离线光追相同的光照模型可以让预计算的光追结果能更容易迁移到实时渲染中。
在各种光照模型的BRDF中,Cook-Torrance是目前游戏工业界最常用的模型。其公式如下:
其中
- D为法线分布项,其描述了在单位面积中有多少朝向方向
的微表面比例。 为 以及 形成的半角向量 。由于Torrance-Sparrow假设微表面能完美反射,因此反射的能量和朝向 方向的微表面比例成正比。 - G为几何遮蔽项,其描述了由于微表面之间相互遮挡导致的自遮蔽阴影造成的能量损失。
- F为菲涅尔项,其描述了光线击中物体表面时反射光线占全部光线的比例。当光线击中物体表面时会有一部分折射进物体内部,这会造成反射的能量损失。而折射现象的强度会随着入射角的变化而变化,这便被称为菲涅尔现象。
正是刻画了这一现象。
Torrance-Sparrow模型分母中的
由于Torrance-Sparrow只描述了镜面反射现象而没有漫反射现象,在实时渲染过程中往往需要加上额外的漫反射项
什么是Early-Z
对于什么是Early-Z首先需要回答为什么深度测试发生在像素着色器之后。
观察渲染管线,你能发现把深度测试放在像素着色器之后十分不合理。因为像素的深度值在光栅化差值之后就已经确定。把深度测试放在像素着色器之前可以提前剔除无需做像素着色器计算的像素。实际上有3种情况导致深度测试必须在像素着色器之后
clip/discard操作:任何形式的片元丢弃操作,如clip或discard,都会使得Early-Z失效,因为这些操作可能会在深度写入之后发生,从而导致错误的深度信息被写入1
某些特殊情况下,像素着色器也能输出深度值。
反过来说,如果渲染命令中避免了这3种情况,深度测试是可以提前到光栅化之前的。而提前后的深度测试的技术就是Early-Z 。Early-Z是硬件优化技术,当GPU检查到当前的渲染命令能启用Early-Z时,Early-Z就会被启用。
移动端GPU架构 TBR/TBDR
关于移动端GPU的结构可以看视频
在传统的直接渲染方式中,GPU会遍历每个三角形并立即光栅化。对于有大量物体的复杂场景,这些三角形相互遮挡进而导致被光栅化的大部分像素结果都覆盖。如果GPU还像立即模式在每个三角形光栅化后立刻将结果写到frame buffer中这会造成大量无用的总线带宽消耗,这在移动端会造成发热等问题。
为了解决这个问题,移动端往往采用TBR的光栅化方式。具体来说,TBR会把需要着色的画面分为若干个
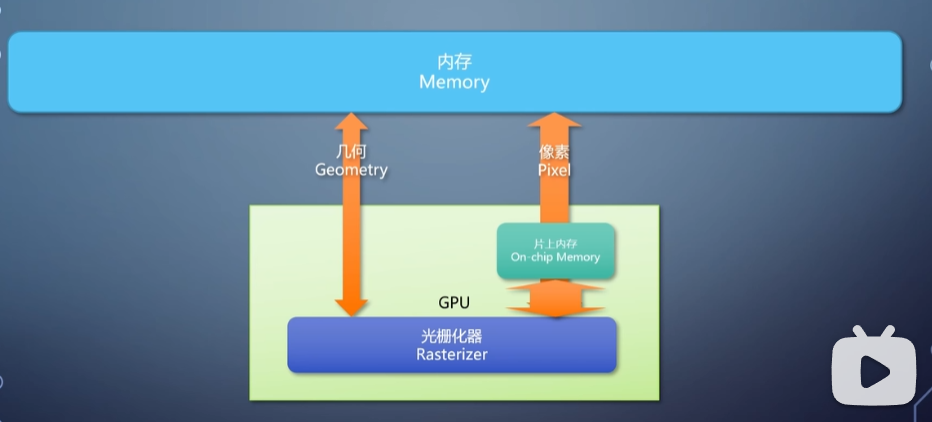
TBR包括以下几个步骤:
- 遍历所有三角形,每个三角形和tile逐个求交。记录哪些三角形和各个tile相交。
- 将Tile的frame buffer加载到cache,遍历并光栅化与该Tile相交的三角形,将光栅化结果写入cache中。
- 将cache内容写入内存。
相比立即模式,TBR虽然能避免额外被遮蔽像素的带宽消耗,但引入了加载各个tile的消耗。因此当渲染过程 中多次切换render target的时候,TBR会为加载tile造成性能问题。如图所示,可以看到相比第一种情况,为了渲染到Render Target 2,TBR用了额外的Load和Store操作。
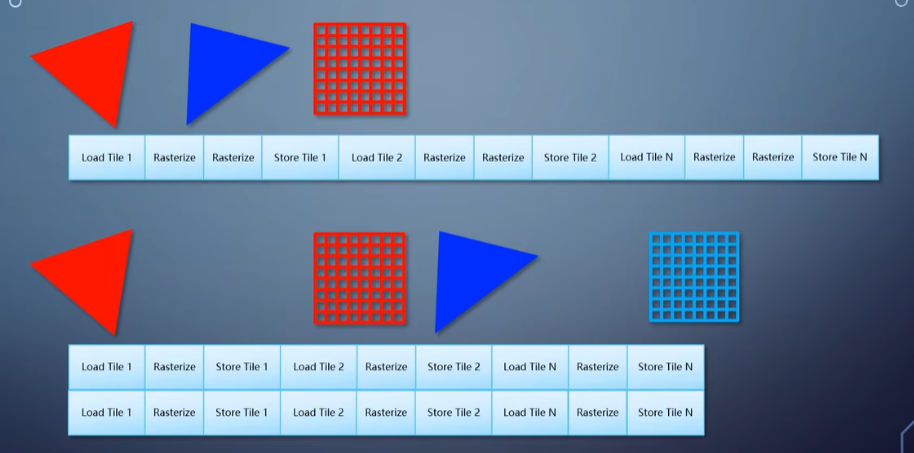
对于这个问题vulkan的解决办法是引入render pass的概念。render pass是一组共用相同frame buffer的一组命令。根据每个命令对frame buffer的用法不同分为不同的sub pass(例如,sub pass 1需要写入frame buffer[0], sub pass 2需要读取frame buffer [0]),两个 sub pass之间可以设置barrier解决读写冲突。这使得同一组render pass内的命令不存在frame buffer的切换。
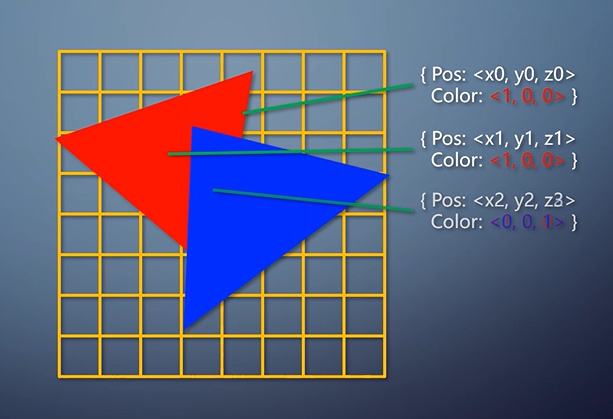
TBDR在TBR以及Early-Z的基础上发展而来,其写入Cache的不再是像素着色器的结果,而是光栅化插值的结果。这样,可以省略被遮蔽像素的像素着色过程。
物理模拟
什么是CCD
参考文献 (关于CCD找到了一些论文,但因为内容实在太多遂放弃)
CCD全称Continuous Collision Detection,连续碰撞检测。是为了应对物理引擎无法在较大时间步长内,无法捕捉到高速运动物体的碰撞的情况(例如,高速移动的子弹穿过墙壁)。一般游戏引擎中有这几种解决方案:
- Sub-Stepping: 将一个完整的时间步长划分为多个子步长,以子步长为单位迭代。
- 二分法:和Sub-Stepping结合使用一般用于sub-stepping准确的碰撞点的求解
- Raycast: 常用于射击游戏子弹的碰撞检测,用Raycast结果代替子弹刚体的碰撞。
- 球体Trace:可以看作是Ray cast的延伸。将刚体当前帧的位置作为起点,下一帧无碰撞情况的运动后位置作为终点,做一个球体的轨迹检测。
- Speculative CCD:将碰撞体积扩大,获取全部潜在碰撞点,从中选取最优。这可以解决球体Trace中无法检测旋转物体的问题。




